
There’s so many tools and platforms for ETL (Extract, Transform & Load) and ELT (yes, same words but workflow geared towards interim data lake prior to warehousing or database). All we want to do is get the source data, do some basic transformations (improve field naming, update data types, replace special characters for nulls etc) and put it somewhere manageable, like a database or data warehouse. We don’t want a data swamp (raw and unusable records) and we do want to improve data quality at this stage – and alert in case action required. Completely crap data means we need to improve processes quickly before vital data is lost.
We lost some enthusiasm for Power Query within Microsoft’s Azure Data Factory (see azure-data-factory-power-query) although it just needs catching up, but ultimately we know we’d all be better off with a wider and more open source solution – in Python. And guess what? Microsoft realise that is an itch to scratch and have added a Data Wrangler extension to the fantastic (and free!) Visual Studio Code. Where you can already use an extension to manage your Azure cloud resources, like the Data Lake or Storage you’re accessing in the first place. Perfect. If it works. And it does, so far!
Well, in an enterprise environment where the data is stored remotely and not inside the Python project, you need some fiddling to get Data Wrangler to even open as only a tiny button pops up once we’ve hand coded the dataframe:
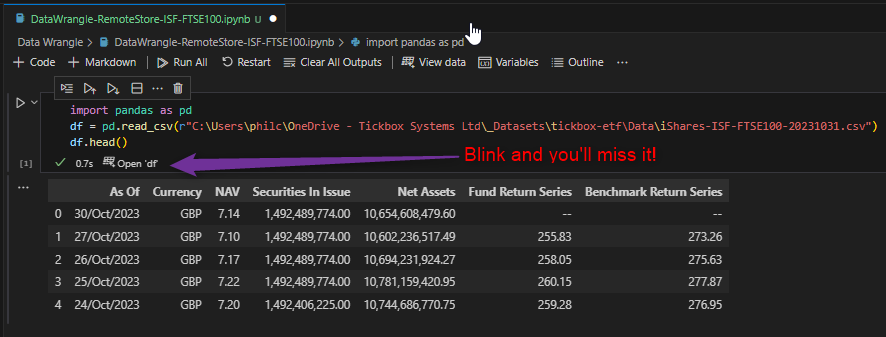
But once open, there’s incredible goodness to be seen immediately:
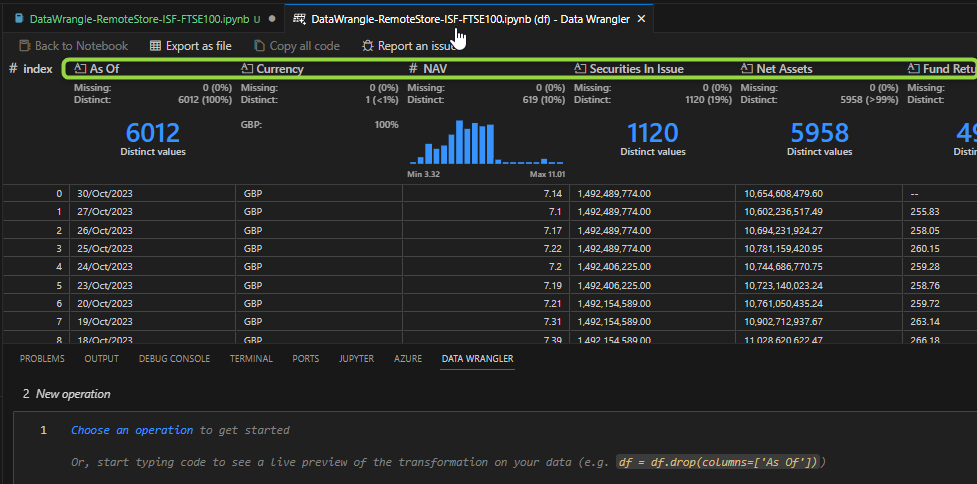
Note the numerics even have instant histogram charts showing data distribution. This gives a quick heads-up on potential accuracy issues, as well as a good feel for the data. The “Distinct Values” headers for categoricals do likewise. It even flags up the number and % of missing data! This is a great head-start to EDA – Exploratory Data Analysis.
Once we’re happy with this reality check, we can get down to the transformations we mentioned up top:
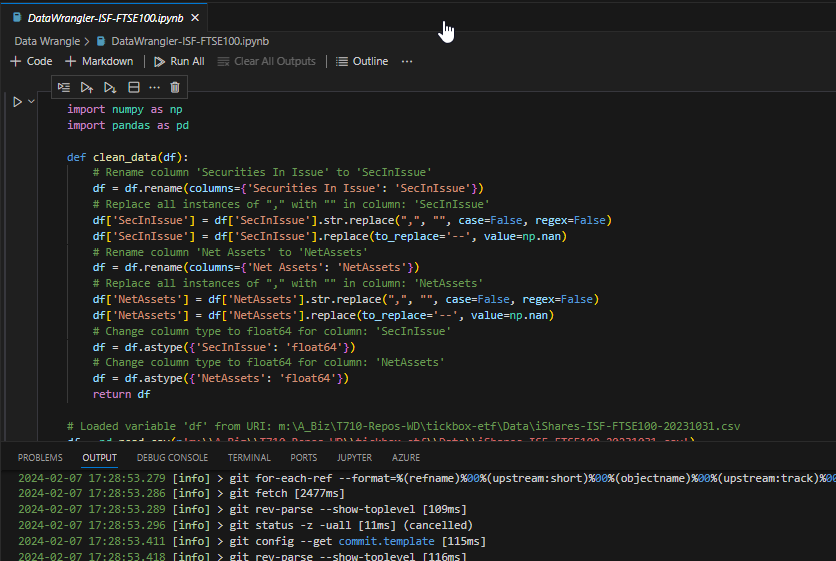
Note from the lower screen that we’ve initialised a new local Git repository and all our code changes can be committed for version control and branching. That’s one of the beauties of doing this in Python rather than some proprietary tool. Most tools have some kind of version control, but it’s often very clunky by being wired into their own system. We can easily add a remote to our local Git to push commits up to GitHub for sharing, pull requests etc. That’s how we like to work and it means you as client can get access and continue the good work with ourselves or your own developers – you’re not bound to us.
From here, we simply save the Python dataframe as another CSV (or other suitable format) ready for ingestion into a database, data warehouse or directly into an analytics tool like Power BI. Now we’re talking!

